SNS投稿やアンケート、商品レビューなど、膨大な量のテキストデータが絶えず生み出されています。
それらの文章の中から有用な情報を抽出・分析する手法が「テキストマイニング」です。
ここではテキストマイニングの意味や仕組み、ビジネスにおける活用方法まで、わかりやすく解説します。
目次
1.テキストマイニングとは?
1-1.定義と基本概念
テキストマイニングとは、
大量の文章の中から共通する特徴や頻出する内容を取り出して、
全体像を把握し、課題解決に役立つヒントを見つけ出すことです。
「マイニング(mining)」という言葉の通り、膨大なテキストデータの中から「価値ある情報を掘り出す」ことを目的としています。
テキストマイニングの主な対象となるのは以下のようなデータです。

1-2.テキストマイニングの目的
テキストマイニングの主な目的は、
大量のテキストデータから意味のある情報を抽出、分析することです。
具体的には、文書の分類、感情分析、トピックモデリング、キーワード抽出などが挙げられます。
これにより、データの背後にあるパターンやトレンドを明らかにし、プロダクト(商品・サービス)の改良や開発アイデアとして役立てることが可能です。
また、感情分析を通じて、ソーシャルメディア上での社会的な反応や意見を把握することも可能です。
現在はテキストマイニングに特化した分析ツールがあるため、データの要約など効率的に分析できます。
1-3.自然言語処理(NLP)との関係
自然言語とは、人が人と会話するときに使う言葉のことです。
一方で、人工的に作られたプログラミング言語(Python、Rなど)は人工言語と呼ばれます。
自然言語処理(NLP: Natural Language Processing)とは、人間の言葉をコンピュータが理解・処理・生成できるようにする技術のことです。人の言葉を対象とするテキストマイニングは、自然言語処理の技術と深い関わりがあります。
その中でも、データから有益な情報を見つけ出す「分析」を得意としています。
■テキストマイニングにおける自然言語処理の役割の例
・形態素解析
日本語を単語に分割する処理をする。
・品詞タグ付け
名詞・動詞などの分類する。
・構文解析
文の構造を把握する。
・固有表現抽出
人名・地名・製品名などの抽出する。
自然言語処理はテキストマイニングを実施するための技術基盤になっているのです。
2.テキストマイニングの仕組み
テキストマイニングは、複数のプロセスを通じてテキストから価値ある情報を抽出します。
ここでは、テキストマイニングの基本的な分析の流れを解説します。
2-1.前処理(クリーニング・形態素解析など)
収集したままのテキストデータは、ノイズやばらつきが多く、そのまま分析に使うには不適切な状態です。
そのため、以下のような「前処理」を行います。
■代表的な前処理手法
・クリーニング
絵文字・記号・URLの除去、重複排除などをします。
※特にSNSはノイズデータ(広告、スパム、ボット、絵文字の羅列など)が多いためこの作業が分析精度に影響します。
・正規化=「辞書の整備」
「たべる」「食べた」「いただく」などの表記ゆれを統一します。
・形態素解析
文章を単語に分割します。
例:
「この商品は使いやすい」 → 「この/商品/は/使い/やすい」
・ストップワード除去
「です」「ある」「こと」「思う」「します」など意味を持たない単語を除外します。
この処理によって、分析に必要な意味のある単語に整理されたデータを用意します。
テキストマイニングツールではこれらの処理も行うことができます。
2-2.辞書の整備
テキストマイニングの精度を高めるには、正規化という「辞書の整備」が不可欠です。
辞書とは、単語や表現を正しく認識するための情報リストで、以下のような役割があります。
・業界用語や略語の登録
「DX」「SaaS」などを正しく認識させる。
・固有名詞の追加
人名、企業名、商品名などを1語として扱う。
・誤認識の防止
たとえば「生成AI」を、「生成」「AI」に分割しないようにする。
・分析精度の向上
不要な分割を防ぎ、より正確な結果を得る。事前に辞書を整えておくことで、無駄なノイズを減らし、より分かりやすく意味のある分析が可能になります。
2-3.分析手法
前処理を終えたテキストデータは、いよいよ具体的な分析フェーズに入ります。目的に応じてさまざまな手法が用いられます。
頻度分析
全体傾向の把握に有効です。
単語の出現回数を集計し、よく使われる語句や話題の傾向を把握する基本的な分析手法です。
自由記述アンケートやSNS投稿、レビューなどの大量データから、注目キーワードや関心の高いテーマを可視化できます。
共起分析
頻度分析よりも発言の背景がとらえやすくなります。
一緒に書かれている単語の組み合わせやパターンを抽出し、言葉と言葉の関連性を可視化する手法です。
「おいしい」「コーヒー」「サンドイッチ」など、同時に語られやすい語句を分析することで、顧客が何に価値を感じているか、どのような要素が結びついているかといったことが可視化されます。
感情分析
顧客満足度の定量的な把握や炎上予兆の検知、マーケティング施策の反応などに活用されます。
文章に含まれるポジティブ・ネガティブ・中立などの感情を自動で分類・評価する手法です。
顧客レビューやアンケート回答などから、肯定的な評価、不満点、怒りや期待などの感情的なトーンを抽出できます。
対応分析
「20代はデザインを重視」「40代は価格を重視」など、属性ごとの特徴語や関心軸を直感的に把握できます。
特定の属性(例:年代・性別・地域など)と単語との関係性を、二次元マップで可視化する手法です。
主成分分析
大量の自由回答やレビューから、全体の流れや重要な視点を見つけたいときに便利な手法です。
そもそも大量の文章は様々な情報があり内容にばらつきがあります。
このばらつきのある情報を要約し、代表的な特徴(=主成分)を抽出する方法です。
たとえば、この分析を使うと「価格重視」「高機能重視」「デザイン重視」といった大まかな傾向にまとめられます。
これらの分析手法はテキストマイニングツールを使えば、ワンクリックで実行できることが多いです。
その為、専門知識がなくてもすぐに分析をすることができます。
2-4.分析結果の可視化
分析の最後のステップは、得られた結果をわかりやすく可視化し、そこからビジネスに活かせる示唆を得ることです。
代表的な可視化方法には以下があります。
■よく使われる可視化の方法
・バーチャート
単語の出現頻度を棒グラフでわかりやすく表示します。
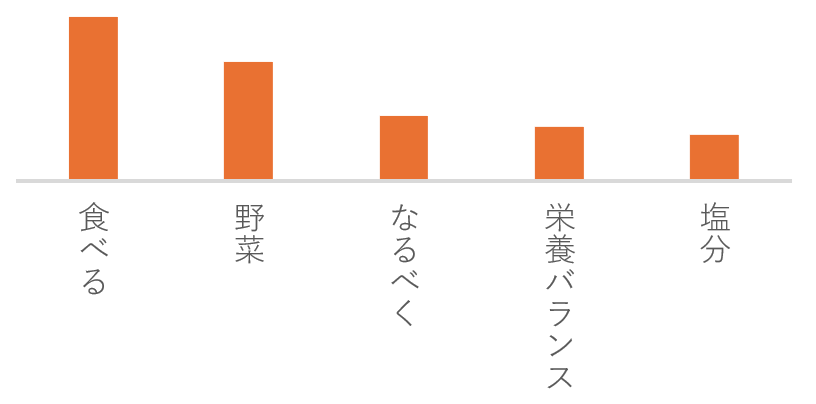
・ワードクラウド
頻出語を視覚的に示し、直感的な理解を助けます。

・共起ネットワーク
単語間のつながりを表現し、関連性やグループを把握できます。
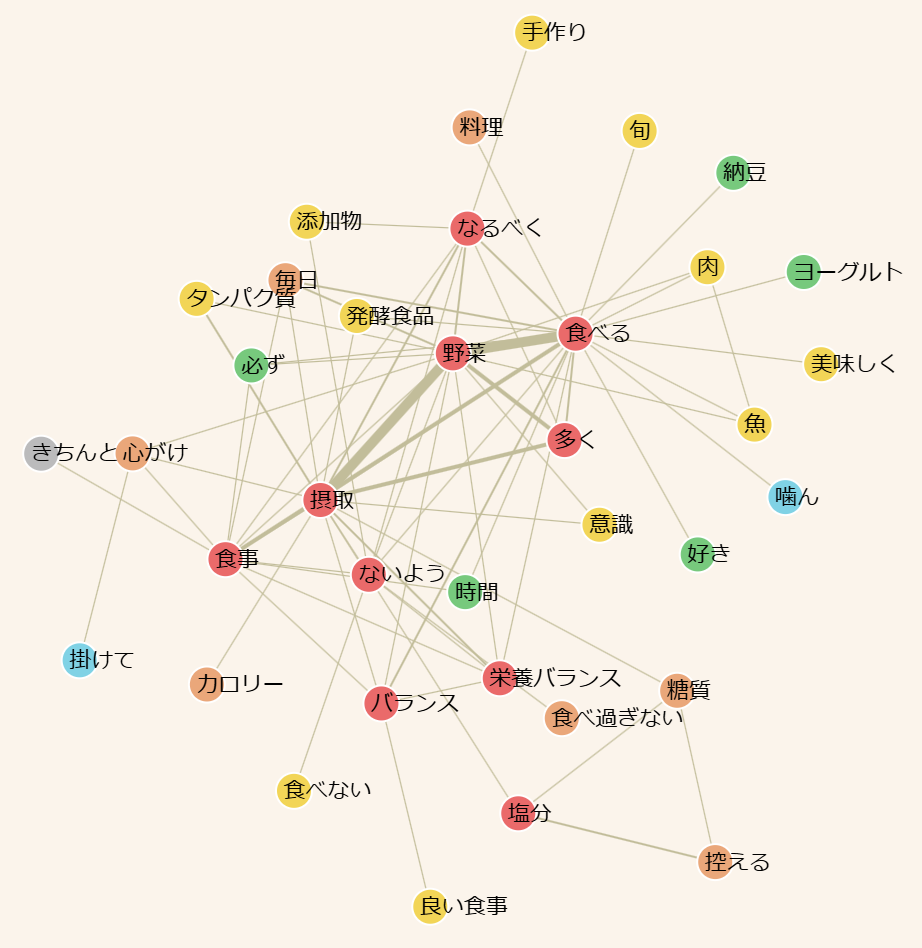
・散布図
対応分析などで単語や属性の関係をマップ上に配置し、類似性を視覚化できます。
テキストマイニングは単なる単語のカウントにとどまらず、以下のような一連のプロセスを経て、意思決定に役立つ情報を生み出します。

各段階で適切なツールと技術を活用することで、ビジネスの課題解決や戦略立案において強力な武器となるでしょう。

3.テキストマイニングの主な活用シーン
テキストマイニングは、業界・部門を問わずさまざまなビジネスシーンで活用されています。
ここでは、特に活用頻度の高い代表的なシーンをご紹介します。
3-1.顧客の声を分析(アンケートの自由回答など)
自由記述には、具体的な体験や細かな不満点、期待などが多様な表現で記載されます。これらを効率よく分析することで、数値だけでは捉えきれない「顧客の本音」を深く理解できます。
■分析例
・頻出分析でキーワード抽出、顧客が何に注目し、どんな点を評価・不満視しているのかを把握する。
・感情分析を活用し、ポジティブ・ネガティブの感情のバランスや傾向を定量化し、改善の優先順位付けを支援する。
・対応分析にて、多様な意見をカテゴリーに分類し、隠れたニーズや新たな課題を発見する。
3-2.コールセンター(VOC:Voice of Customer)を分析
コールセンターでは、電話応対やチャットで顧客から寄せられる生の声を大量に扱います。
VOC(Voice of Customer)は顧客の不満や疑問をリアルタイムで吸い上げる重要な情報源であり、ここから顧客満足度の向上や業務改善につながるヒントが得られます。
テキスト化された通話記録やチャットログを効率的に解析することが求められます。
■分析例
・問い合わせ内容をカテゴリーに分類し、どの問題が多いかを把握、対応の優先順位を明確化する。
・共起分析を行い、よく一緒に発生する問題やキーワードの関連性を抽出。これにより、根本原因の特定や商品・サービスの課題点を発見する。
・トレンド分析で時系列に問い合わせの傾向を追い、季節要因やキャンペーンの影響を分析を行い迅速な対応策立案が可能になる。
3-3.SNSの書き込みを分析
InstagramやX、FacebookなどのSNS上には、ユーザーが製品やサービスについて率直な感想や評価を書き込んでいます。
これらの書き込みはリアルタイムで多様な顧客の意見を反映しており、世間の評判やトレンドを把握するのに非常に有用です。
感情や話題の変化を素早く捉えることで、マーケティング戦略や商品開発に役立てられます。
■分析例
・感情分析によって、肯定的な意見と否定的な意見の割合や傾向を把握し、製品やサービスの評判を評価する。
・ワードクラウドで頻出するキーワードを視覚化し、ユーザーが注目していることや話題を直感的に理解する。
・トレンド分析を活用し、季節やイベントごとの話題の変化や新たに注目されるテーマを追跡する。
・競合比較では、自社製品と競合製品に対するSNS上の反応を比較し、強みや弱みを明確にする。
3-4.内部文書を分析(日報・議事録)
社内の日報や会議の議事録は、業務の進捗や課題、意思決定の過程を記録しています。
しかし、膨大な量のテキスト情報を人力で整理・分析するのは非常に手間がかかります。
テキストマイニングを活用することで、重要な情報の抽出やトピックの整理が効率化され、組織のナレッジ共有や迅速な意思決定を支援します。
■分析例
・トピック抽出により多数の文書から主要なテーマを抽出し、会議で議論された内容や注力すべき課題を把握できる。
・頻度分析を通じて、重要なキーワードや繰り返し指摘される問題点を洗い出す。
・要約が得意な生成AIを活用し、長文の議事録を短時間で要点だけにまとめ、関係者に共有しやすくする。
4.テキストマイニングのメリットと注意点
テキストマイニングの技術によって大量の文章を効率的で、かつ客観的に分析できるようになりました。
ただ、非常に便利である一方で、注意点もあります。
ここでは、そのメリットと注意点をまとめています。
4-1.テキストマイニングのメリット
テキストマイニングを行うメリットは、以下のようなものが考えられます。
■メリット
・大量の文章データから効率よく有益情報を抽出できる。
・顧客ニーズやトレンドを素早く把握できる。
・マーケティング戦略や商品開発の精度向上に活用できる。
・SEO対策で重要なキーワードや関連語を効果的に抽出できる。
・目視や手作業に比べて時間・コストを大幅に削減できる。
・感情分析で顧客満足度や競合分析の役に立つ。
4-2.テキストマイニングの注意点
一方で、導入や運用にあたってはいくつかの課題や注意点もあります。
データの質や前処理の工数、解釈の難しさなど、適切に活用するためには理解しておくべきポイントがあります。
ここでは主な注意点をまとめています。
■注意点
・テキストデータの前処理に手間や時間、専門知識が必要となる。
・言葉のニュアンスや文脈を完全に理解しにくい。
・皮肉や比喩表現などの解析が苦手である。
例)大雨の日に冗談で、今日はいい天気
・データの質や量が不足すると結果の信頼性が低下する。
・専門ツールの導入や運用にコストがかかる。
・運用担当者のスキルやチーム体制の整備が必要で社内リソースの確保が課題となる。
・感情分析の精度は一般的に7~8割と言われ、短文、皮肉、業界特有の言い回しなどが影響します。
5.テキストマイニングのツールの選び方
テキストマイニングのツールは多種多様で、選び方次第で導入効果が大きく変わります。
ここでは、いくつかある選定ポイントをわかりやすく解説します。
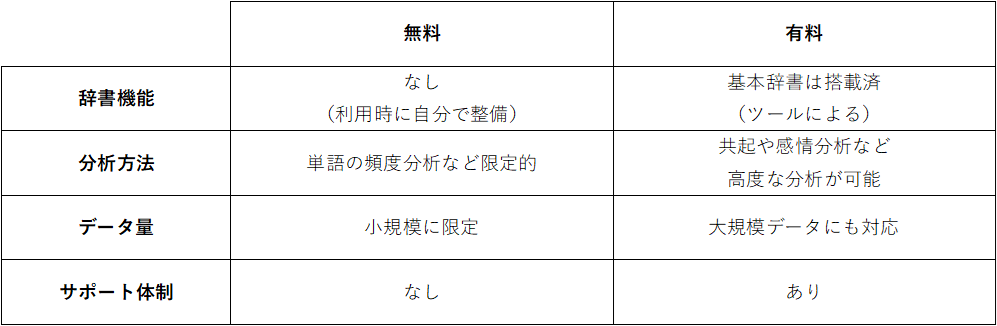
5-1.有料か無料か
無料のテキストマイニングツールの代表として、RやPython、KHCoderなどがあります。
無料と有料の違いは、辞書機能、分析方法、データ量、サポート体制などがあげられます
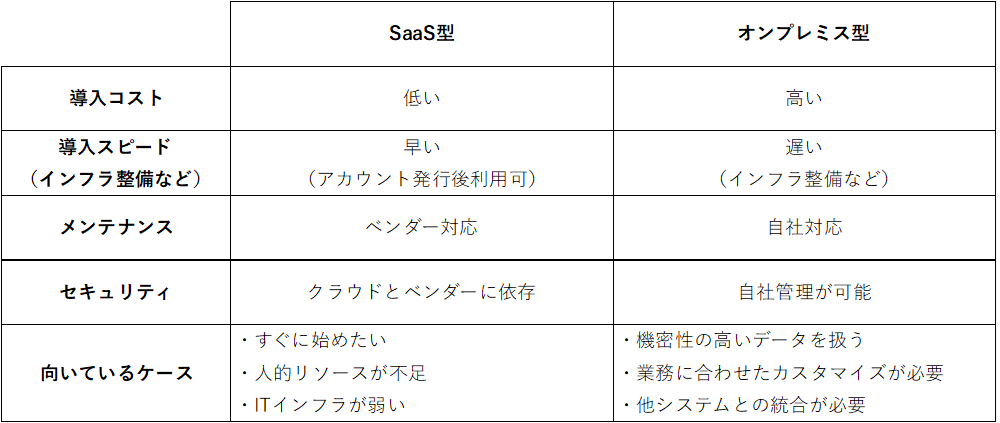
5-2.SaaS型かオンプレミス型か
テキストマイニングツールは、主にSaaS型とオンプレミス型の2種類に分かれます。
自社のセキュリティポリシーや運用体制を踏まえた検討が必要になります。
5-3.分析精度、操作性、導入しやすさで比較
ツールの選び方にはいくつかのポイントはありますが、主に3つの視点で比較するとよいでしょう。
■分析の精度
・形態素解析や感情分析の精度はツールによって大きく異なります。
・業界用語、固有名詞などは初めに辞書整備が必要ですが、整備のしやすさが分析工数にも影響してきます。
■操作性(ユーザビリティ)
・専門知識がなくても直感的に使えるか、特に引継時に後任が容易に使えることは重要になります。
・分析アウトプットの見やすさ、解釈の容易さはツールの理解しやすさに直結します。
■導入のしやすさ
・初期設定やデータ連携が容易かどうかは、導入時の負担を大きく左右します。
・サポート体制やトレーニングの有無も、スムーズな運用開始を目指すならば気を付けたいところです。
・コスト面(初期費用・月額費用)は、導入判断の際の大きなポイントとなります。
これらの観点から自社のリソースや目的に合ったツールを選ぶことで、効果的なテキストマイニング活用が可能になります。
6.テキストマイニングツール活用事例
テキストマイニングツールは多様な業界で活用されており、顧客の課題解決に貢献しています。
とくにSaaS型は導入費用の安さ、スピードなどから利用している企業が増えています。
ここでは、テキストマイニングの活用事例を紹介し、効果的な利用方法をご案内します。
6-1.導入事例紹介
食品メーカー
新商品発売後に実施されるアンケートの自由回答欄から、味やパッケージ、価格に関する消費者のリアルな声を分析したく導入した。
ポジティブ・ネガティブの傾向を可視化することで、商品改良や次回開発のヒントを得ることができた。
また、訴求していた特徴が伝わっていたのか、回答内容から浸透状況を把握することもできた。
家電メーカー
ECサイトやレビューサイトに投稿された口コミや評価コメントを収集し製品ごとの評価傾向を可視化したく導入した。
「音が静か」「操作が複雑」といった具体的な意見をカテゴリ別に整理することで、製品改良やカスタマーサポートの強化に役立てることができた。また、競合製品との比較分析もでき、自社製品の現状を把握できた。
化粧品メーカー
お客様相談室に寄せられる電話やメールの内容をテキストマイニングで分析し、よくある質問やクレーム内容を体系的に把握したく導入した。
「肌に合わない」「使い方が分からない」といった傾向をつかむことで、取扱説明やFAQの見直し、さらには製品開発にも活用することができた。
保険会社
契約手続きや給付金請求に関する問い合わせ内容をテキストマイニングで分類・集計し、顧客がつまずきやすいポイントを明らかにしたく導入した。
分析結果をもとに、ウェブサイト上の説明やFAQを改善するほかチャットボットの応答精度向上にも貢献でき、顧客満足度向上に役立った。
アパレル
X(旧Twitter)やInstagramなどSNS上に投稿された商品の感想やファッションタグを収集・分析することで、消費者のトレンドやブランドイメージを把握したく導入した。
「かわいい」「今っぽい」といったキーワードの出現頻度や文脈を分析し、新商品の企画やプロモーション施策に活かすことができた。
旅行・観光業
宿泊予約サイトや観光レビューサイトに投稿された自由回答を分析し、顧客が高く評価するポイントや不満点を抽出したく導入した。
評価の高いポイント、低いポイントなどを具体的な声から分析することで、サービス改善や新たな企画に結び付けることができた。
また、特定地域の評価や印象などから地域ブランディングにも活用できた。
広告代理店
広告出稿後やキャンペーン実施後、SNS上のコメントを分析することで、反応や感情の変化を可視化したく導入した。
ハッシュタグや商品名と共に投稿されたコメントを収集し、「面白い」「買ってみた」「期待外れ」などのワードをカウントする。
この投稿数の推移やポジネガ比率を時系列で見ることで、広告の話題性やブランドへの影響を測定することができ、次回施策へのフィードバックにも活用された。
7.テキストマイニングとAIの関係
生成AIの進化により今後テキストマイニングツールはどうなっていくのでしょうか。
従来のテキストマイニングツールは頻出語の正確なカウント、感情分析、クラスタリング、カテゴリー分類など、定量的で構造化された分析を得意としてきました。
一方、生成AIは、文脈理解や要約、説明生成といった、非構造化データから意味を生成する能力に優れています。
つまり、
テキストマイニングは、
「大量のデータを見やすく可視化・パターンを整理する技術」
生成AIは、
「データから文脈や意図を読み取り、人の言葉で説明する技術」
という補完関係にあります。
7-1.生成AIにできること
・生成AIを統合したテキストマイニングツールが主流に
たとえば、「この商品に対する口コミの要点をまとめて」と聞くだけで、生成AIがテキストマイニングの分析結果(キーワード・ポジネガ分析など)を踏まえて、要約や洞察を生成してくれる。
・分析結果の「解釈・説明」が自動化される
従来は分析者がグラフや図を読み解きレポートにまとめていました。
これが生成AIによって自動化されるので、人の作業や負担が減り、意思決定のスピードが上がります。
・高度な定性分析も可能に
生成AIは、ニュアンスを含んだ文章の意味解釈に強いため、「文脈ベースのクラスター分類」が可能になります。
たとえば、「期待していたけどちょっと違った」というコメント群と、「正直がっかりした」という群は、従来は「ネガティブ」で一括りすることが一般的でした。
生成AIなら、「期待外れ系の反応」と「強い否定的反応」 といったニュアンスでクラスターを分けることができます。
このような分析をできるツールもありますが、分析者が結果を見ながら辞書整備や解釈をしていく必要があります。
ニュアンスの違いや感情のグラデーションなど意味理解の深さが圧倒的に高いのは生成AIの特徴です。
7-2.テキストマイニングは「なくなる」のではなく「進化する」
テキストマイニングは、AIの進化によって人の感覚や思考により近い分析が可能になります。
両者を組み合わせれば、精密かつ立体的なインサイトが得られます。
正確な数で全体を俯瞰し、AIで深層を読み解く、この両輪を活用することで、テキスト分析の精度と実用性は大きく向上します。
8.テキストマイニングをマーケティングに活かしていきましょう
生成AIの進化により単なる単語の出現頻度だけでなく、文章の流れや感情の微妙な違いまで理解できるようになってきました。
その結果、より深く実用的な気づきを得られる時代となっています。
しかし、ツールが自動で「答え」を示すのではなく、分析者の視点や問いかけと組み合わせてこそ、本当に価値あるインサイトが生まれます。
業種や目的に合わせてテキストマイニングやAIを賢く使いこなし、
データに潜む発見をビジネスの成功につなげていきましょう。